Текст в 8-битной кодировке очень легко обрабатывать в компьютере (а также, если это нужно, кодировать или декодировать вручную). Но на этом достоинства 8-битной кодировки кончаются.
Применение компьютеров стало глобальным; их можно найти практически в любой стране мира, с самыми разными языками. Многообразие кодировок, требуемых для всех этих языков, становится заметной помехой – в частности, при международной передаче данных. А если требуется подготовить документ на нескольких разных языках, 8-битная кодировка вообще оказывается непригодна.
Также её недостаточно для языков с иероглифическим письмом – таких, как китайский и японский. Количество разных символов, требуемых даже для одного-единственного подобного языка, исчисляется тысячами. Закодировать иероглифический текст в 8-битной кодировке просто невозможно – какой бы она ни была.
Чтобы решить все эти проблемы, необходим переход на многобайтовые кодировки. При использовании такой кодировки символу соответствует уже не один, а несколько байт. Причём разным символам может соответствовать разное количество байт.
Существует стандарт многобайтовой кодировки – ISO 10646, Unicode. Он предусматривает несколько разных вариантов кодирования. Из них наиболее распространён так называемый UTF-8.
В кодировке UTF-8 символы таблицы ASCII (буквы английского языка и т.д.) по-прежнему представлены одним байтом. Для других символов – в частности, кириллицы – используется по два или три байта.
Причём в Unicode входит не только кириллица для русского и других современных языков, но даже буквы старорусского языка, такие как “ять” и “фита”. Хватило места и для многих других алфавитов.
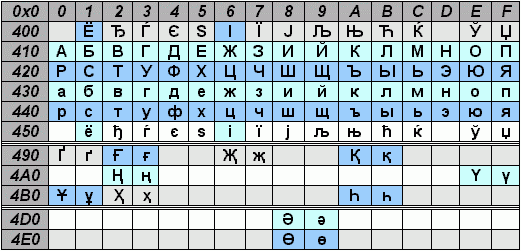
Unicode
Многобайтовые кодировки, в частности Unicode – будущее компьютерной техники. Но на данный момент к работе с ними приспособлены ещё далеко не все программы. Поэтому 8-битное кодирование текста остаётся весьма распространённым.

